| cubbi.com: Fibonacci numbers in many programming languages |
www.cubbi.com
personal
programming
fibonacci numbers
forth examples
postscript examples
muf examples
joy examples
j examples
scheme examples
hope examples
ocaml examples
haskell examples
prolog examples
c++ examples
java examples
assembly language examples
fortran examples
c examples
sh examples
awk examples
perl examples
tcl examples
asmix
hacker test
resume
science
martial arts
fun stuff
www.cubbi.org
Fibonacci numbers are defined as follows
Note that examples and benchmarks made before september 2009 on this page use the older, less general, definition, with F(0) = 1.F(0) = 0
F(1) = 1
F(n) = F(n-1) + F(n-2)
for negative n: F(-n) = (-1)n+1F(n)
September 2009 UPDATE:
UPDATE IN PROGRESS: Five years since I wrote this page, I've decided to rewrite all examples to be more useful, the subroutines will be as general as possible (no more 2x2 matrix multiplication), all code will be commented, each example will now take its arguments from command line (where possible)
April 2014 UPDATE:
This effort was abandoned somewhere in 2010.
ALGORITHMS AND BENCHMARKS SUMMARY
| 1. EXPONENTIAL COMPLEXITY | ||
|---|---|---|
| 1A - naive binary recursion execution time: T(n)=to*φn |
asm java C |
to=2.8 ns to=3.0 ns to=3.1 ns |
| 2. LINEAR COMPLEXITY | ||
| 1B - cached binary recursion / memoization | pending 2009/2010 update | |
| 2A - cached linear recursion / infinite lazy-evaluated list | pending 2009/2010 update | |
| 2B - linear recursion with accumulator | pending 2009/2010 update | |
| 2C - imperative loop with mutable variables | pending 2009/2010 update | |
| 3. LOGARITHMIC COMPLEXITY | ||
| 3A - matrix multiplication | pending 2009/2010 update | |
| 3B - fast recursion | pending 2009/2010 update | |
| 3C - Binet's formula with rounding | pending 2009/2010 update | |
EXAMPLES
| Languages | Algorithms | |||||||
|---|---|---|---|---|---|---|---|---|
| 1A | 1B | 2A | 2B | 2C | 3A | 3B | 3C | |
| concatenative languages (program is a composition of functions applied to stack of arguments) | ||||||||
| Forth (1960) | OK | OK | OK | OK | OK | OK | OK | OK |
| PostScript (1982) | OK | OK | OK | OK | OK | OK | OK | OK |
| MUF (1989) | OK | OK | OK | OLD | OLD | OLD | OLD | OLD |
| Joy (1999) | OK | OLD | OLD | OLD | OLD | OLD | OLD | |
| possible todo: Factor | ||||||||
| Vector languages (program is a composition of functions applied to a multidimentional array argument) | ||||||||
| J (1990) | OK | OK | OK | OK | OK | OK | OK | OK |
| possible todo: APL, K, Q, Nial | ||||||||
| functional languages (program is an application of functions) | ||||||||
| Scheme (1975) | OK | OK | OK | OK | OK | OK | OK | OK |
| Hope (1978) | OK | OK | OK | OK | N/A | OK | OK | OK |
| OCaml (1989) | OK | OK | OK | OK | OK | OK | OK | OK |
| Haskell (1990) | OK | OK | OK | OK | N/A | OK | OK | OK |
| possible todo: Clojure, Pure | ||||||||
| logic and concurrent languages (program is a collection of logic statements) | ||||||||
| Prolog (1971) | OK | OK | OK | OK | OK | OK | OK | OK |
| possible todo: KL1, Erlang | ||||||||
| object languages (program is a list of data objects and their relationships) | ||||||||
| C++ (1986) | OK | OK | OK | OK | OK | OK | OK | OK |
| Java (1995) | OK | OK | OK | OK | OK | OK | OK | OK |
| possible todo: C#, Python | ||||||||
| imperative languages (program is a sequence of commands to the CPU) | ||||||||
| Assembly (1952) | OK | OLD | OLD | OLD | TBD | OLD | TBD | |
| Fortran (1954) | OK | OLD | OLD | OLD | OLD | OLD | ||
| C (1972) | OK | OK | OLD | OK | OK | OLD | OLD | OLD |
| sh (1972) | OK | OLD | OLD | OLD | OLD | OLD | OLD | |
| awk (1978) | OK | OLD | OLD | OLD | OLD | OLD | OLD | |
| perl (1987) | OK | OLD | OLD | OLD | OLD | OLD | OLD | |
| Tcl (1990) | OK | OLD | OLD | OLD | OLD | OLD | OLD | |
ALGORITHMS AND BENCHMARKS IN DETAIL
Please remember that these benchmarks do not show strength or weakness of any programming language. All they show is how efficient specific language translators are at implementing the featured algorithms. It is currently (as of 2009) in the transitional stage from OLD to NEW benchmarks using modern hardware and better written examples.
Benchmarked on Intel Pentium Core i7 2.66GHz running Linux 2.6.31 with 12GB RAM, in x86_64 mode
OLD benchmarks: Intel Pentium 4 2.20GHz running Linux 2.5.75 with 640M RAM
NEW RAW BENCHMARK DATA available if you want to see them, as well as
OLD RAW BENCHMARK DATA.
| ALGORITHM 1A: NAIVE BINARY RECURSION | ||||
|---|---|---|---|---|
This algorithm was implemented directly in all languages featured on this web page, since all of them allow recursion. Only Fortran did not allow recursion in the past, but it is supported since the 1990 standard. Curiously, Java outperforms C++ on this test, but it's one of the very few artifical tests where it does so | ||||
| Language | Translator [*] | T0 | T(46), seconds | |
| Assembly | GNU as 2.19.1 [c] | 2.8 ns | 11.63 | 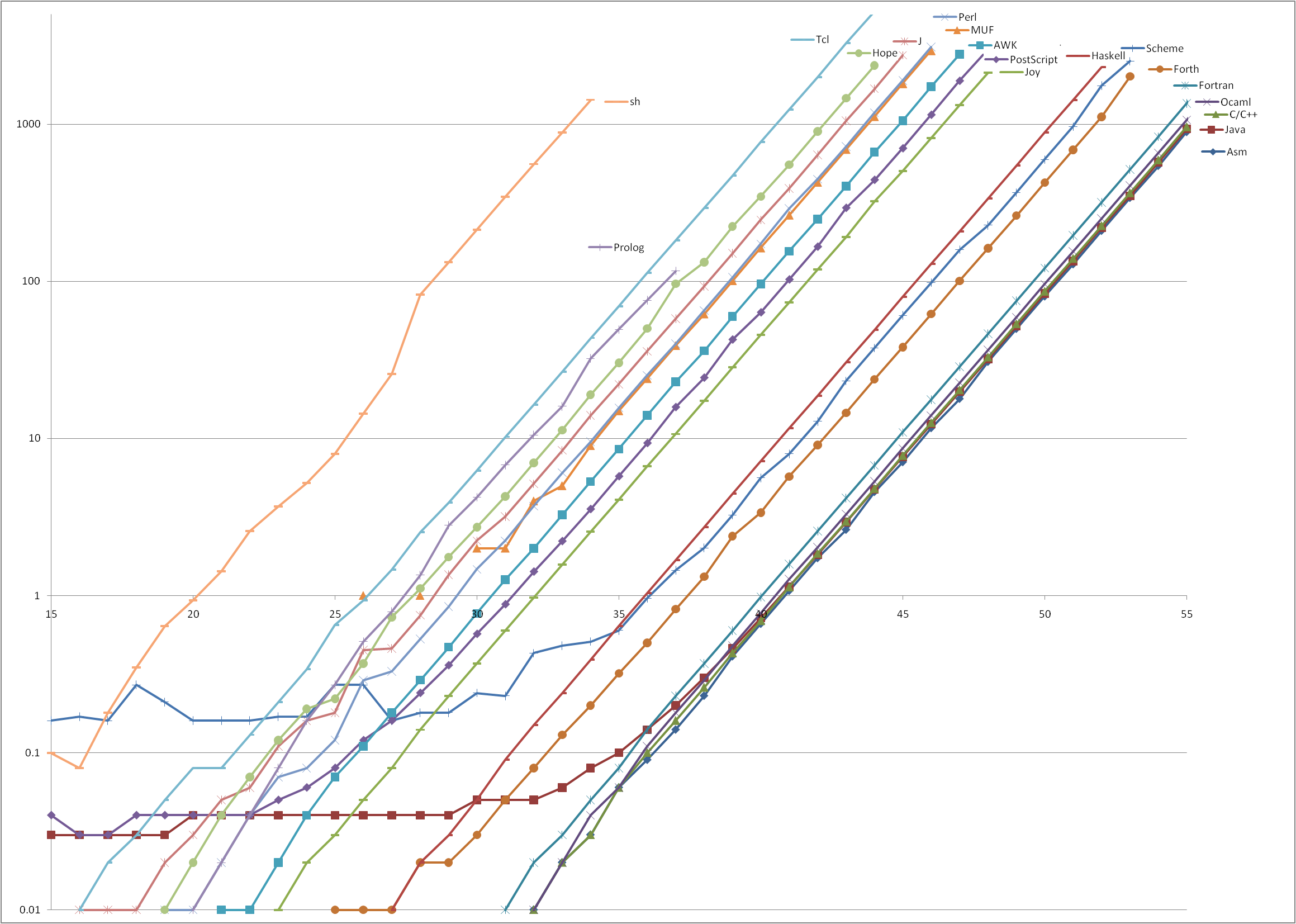 log(Execution time, seconds) vs. Fibonacci number calculated |
| Java | Sun Java SE 1.6.0_16-b01 / HotSpot 64-Bit VM 14.2-b01 [b] | 3.0 ns | 12.34 | |
| C | GNU gcc 4.4.1 [c] | 3.1 ns | 12.57 | |
| C++ | GNU g++ 4.4.1 [c] | 3.1 ns | 12.61 | |
| OCaml | INRIA OCaml 3.11.1 [c] | 3.4 ns | 13.98 | |
| Fortran | GNU gfortran 4.4.1 [i] | 4.3 ns | 17.62 | |
| Forth | GNU gforth 0.7.0 [i] | 15.3 ns | 61.91 | |
| Scheme | MIT Scheme 7.7.90 20090107 [b] | 22.6 ns | 98.04 | |
| Haskell | GHC 6.8.2 [c] | 31.3 ns | 129.1 | |
| Joy | Joy1 by Manfred von Thun, 07-May-03 [i] | 199 ns | 813.5 | |
| PostScript | GPL Ghostscript 8.70 [i] | 284 ns | 1147 | |
| awk | GNU Awk 3.1.7 [i] | 417 ns | 1729 | |
| MUF | FuzzBall MUCK 6.09 [b] | 716 ns | 2939 | |
| perl | perl 5.8.8 [i] | 755 ns | 3101 | |
| J | Jsoftware J64 6.02 [i] | 1.08 μs | 4386 | |
| Hope | Hope by Ross Paterson, 08-Dec-03 [i] | 1.52 μs | 6035 | |
| Prolog | SWI Prolog 5.6.64 [b] | 2.17 μs | 8900 | |
| Tcl | Tcl 8.5.7 [i] | 3.37 μs | 13700 | |
| sh | bash 4.0.33(2) [i] | 101 μs | 415000 | |
Execution time is user time as reported by time(1) except for MUF, where an internal time function was called from the program. T(46) was measured directly only when it was less than 2000 seconds, otherwise it was extrapolated from execution times for smaller inputs. In all cases I tried to pick the fastest one of the language translators that are readily available and offer unlimited precision integer arithmetics (it becomes important in further tests).
| ALGORITHM 1B: CACHED BINARY RECURSION / MEMOIZATION | ||||
|---|---|---|---|---|
Since no function result is calculated twice, the number of additions required to calculate F(n) is reduced to n. The number of cache lookups is instead exponential but, assuming it is implemented as a suitable random-access data structure (array or hash table), the time of each cache lookup is O(1). Space requirements for this algorithm are still exponential because of binary recursion. In the programming languages that have built-in support for memoization (such as J or Factor), algorithm 1A can be turned into 1B with just one keyword. For other languages, I manually implement a suitably generic data structure. | ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
 sqrt(Execution time, seconds) vs. Fibonacci number calculated | ||||
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
| ALGORITHM 2A: CACHED LINEAR RECURSION | ||||
|---|---|---|---|---|
When previously calculated Fibonacci numbers are stored in a data structure,
there is no need for binary recursion, the entire structure can be filled
with only n iterations.
| ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
 sqrt(Execution time, seconds) vs. Fibonacci number calculated | ||||
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
| ALGORITHM 2B: LINEAR RECURSION WITH ACCUMULATOR | ||||
|---|---|---|---|---|
| ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
| Haskell | GHC 6.8.2 [c] | 12.4 fs | 12.42 | 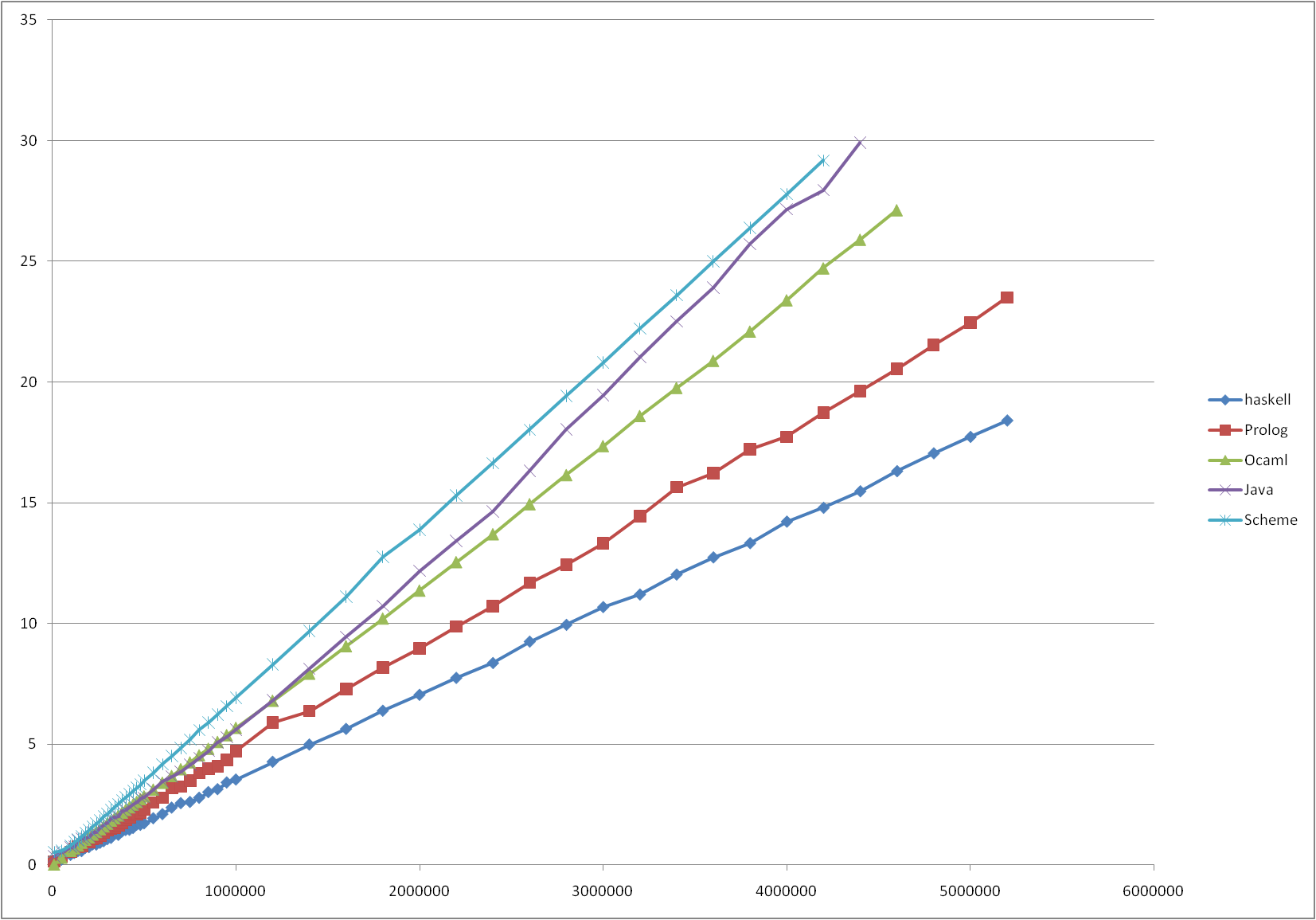 sqrt(Execution time, seconds) vs. Fibonacci number calculated |
| Prolog | SWI Prolog 5.7.15 [b] with GMP 4.3.1 | 21.3 fs | 22.22 | |
| OCaml | INRIA OCaml 3.11.1 [c] | 32.2 fs | 32.14 | |
| Java | Sun Java SE 1.6.0_16-b01 / HotSpot 64-Bit VM 14.2-b01 [b] | 34.1 fs | 31.27 | |
| Scheme | MIT Scheme 7.7.90 20090107 [b] | 48.8 fs | 47.88 | |
| Forth | GNU gforth 0.7.0 [i] | - | - | |
| C++ | GNU g++ 4.4.1 [c] with GMP 4.3.1 | - | - | |
| J | Jsoftware J64 6.02 [i] | - | - | |
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
J reports stack overflow when trying to calculate numbers over ~3000, and I could not find a way to increase available stack size in jconsole
C++ linked with GMP consumes memory at a very large pace, exceeding 20Gb when calculating 500,000th number
Forth (Gforth linked with GMP) also consumes memory at a very large pace, running into tens of gigabytes about the 500,000th number
| ALGORITHM 2C: IMPERATIVE LOOP WITH MUTABLE VARIABLES | ||||
|---|---|---|---|---|
| ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
| Forth | GNU gforth 0.7.0 [i] with GMP 4.3.1 | 11.1 fs | 11.13 | 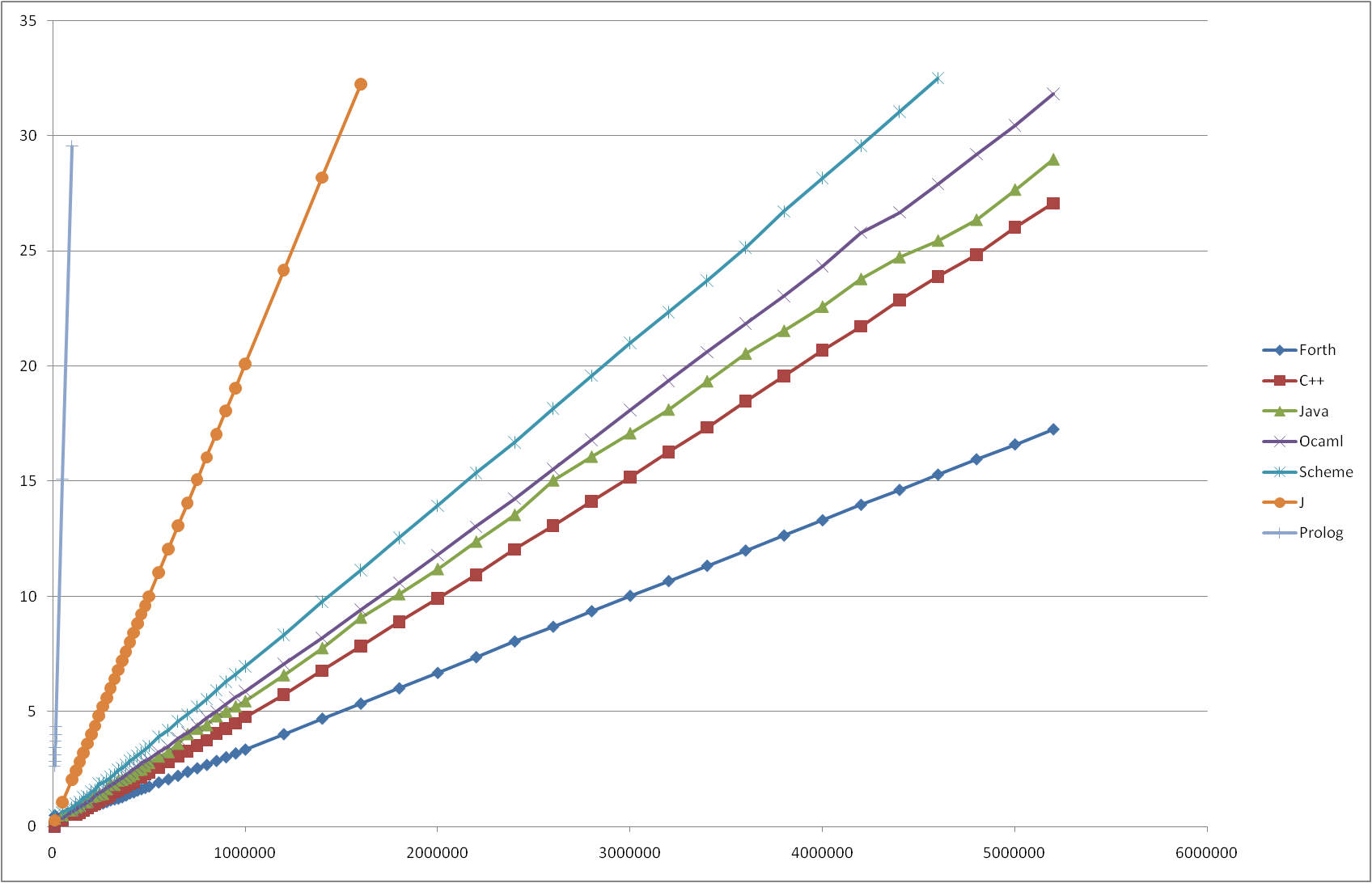 sqrt(Execution time, seconds) vs. Fibonacci number calculated |
| C++ | GNU g++ 4.4.1 [c] with GMP 4.3.1 | 23.2 fs | 22.62 | |
| Java | Sun Java SE 1.6.0_16-b01 / HotSpot 64-Bit VM 14.2-b01 [b] | 31.6 fs | 29.52 | |
| OCaml | INRIA OCaml 3.11.1 [c] | 35.9 fs | 34.52 | |
| Scheme | MIT Scheme 7.7.90 20090107 [b] | 50.8 fs | 48.46 | |
| J | Jsoftware J64 6.02 [i] | 413 fs | 403.6 | |
| Prolog | SWI Prolog 5.7.15 [b] with GMP 4.3.1 | 73.8 ns | - | |
| Haskell | GHC 6.8.2 [c] | - | - | |
| Hope | Hope by Ross Paterson, 08-Dec-03 [i] | - | - | |
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
Prolog usually does not have mutable variables, but some implementations do.
Haskell does not have the concept of mutable variables.
Hope does not have the concept of mutable variables.
| ALGORITHM 3A: MATRIX MULTIPLICATION | ||||
|---|---|---|---|---|
This is the most mathematically elegant way to calculate a Fibonacci number.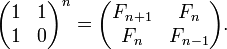 Complexity (fixed precision): O(log n) speed, O(1) space Complexity (unlimited precision): O(n log2 n log log n) speed, O(n) space The repeated squaring algorithm for calculation of xn:
| ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
 sqrt(Execution time, seconds) vs. Fibonacci number calculated | ||||
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
| ALGORITHM 3B: FAST RECURSION | ||||
|---|---|---|---|---|
This algorithm can be derived either from from the fact that, from definition,
F(n+m)=F(n)F(m) + F(n-1)F(m-1), or by rewriting the matrix equation using the
fact that An+m=AnAm: 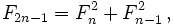 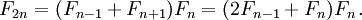
This algorithm is faster than than 3A because it does not repeat calculations of the same numbers (top right and bottom left corners of the matrix in 3A), but it cannot be easily implemented as a tail-recursive function, resulting in O(log n) space complexity. I implement it this way:
| ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
sqrt(Execution time, seconds) vs. Fibonacci number calculated | ||||
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
| ALGORITHM 3C: BINET'S FORMULA WITH ROUNDING | ||||
|---|---|---|---|---|
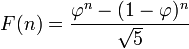
Where φ is the golden ratio, (1+sqrt(5))/2. Because (1-phin) / sqrt(5) is less than 1/2 for all positive n, this formula can be simplified to nearest integer to φn/sqrt(5) or, using the floor function, 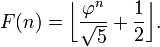
Complexity (fixed precision): O(log n) speed, O(1) space Complexity (unlimited precision): O(n log2 n log log n) speed, O(n) space Evaluation of this formula, just as evaluation of the formula in 3A, is thus reduced to taking an integer power of a number, only this number is irrational and must be represented as a floating-point value with sufficient precision to produce the correct fibonacci number. Not many languages support arbitrary precision floating point values, I use GNU MP library where possible. The computational and space complexity of this algorithm are the same as 1A, and are the same as the complexity of the repeated squaring algorithm with one addition: time to calculate the square root of five with sufficient precision. Where not provided by the compiler/library, I iteratively calculate inverse square root via y(n+1) = 0.5*y(n)*[3 - a*y(n)^2] because this recurrent expression has no division. | ||||
| Language | Translator [*] | t0 | T(1,000,000), seconds | |
sqrt(Execution time, seconds) vs. Fibonacci number calculated | ||||
Execution time is user time as reported by time(1), the test programs were modified to avoid conversion of the entire result to string, since that operation may be slow for large numbers.
LINKS
Wolfram's MathWorld entry
OEIS entry
|
|
![[Valid CSS!]](http://cubbi.org/images/vcss.gif)
![[Valid ISO-HTML!]](http://cubbi.org/images/v15445.gif)
![[Powered by Linux]](http://cubbi.org/images/powered_by_linux.gif)